
手把手教你抓取博客文章实现博客迁移功能
现在的技术博客(社区)越来越多,比如:imooc、spring4All、csdn或者iteye等,有很多朋友可能在这些网站上都发表过博文,当有一天我们想自己搞一个博客网站时就会发现好多东西已经写过了,我们不可能再重新写一遍,况且多个平台上都有自己发表的文章,也不可能挨个去各个平台ctrl c + ctrl v,so,今天“小码”就教各位如何快速、便捷的做博客迁移! Let's go!
第一步,技术选型
今天分享的功能使用了开源的爬虫框架:WebMagic(http://webmagic.io/)
WebMagic是一个国产的、简单灵活的Java爬虫框架。它有以下特点:
简单的API,可快速上手
模块化的结构,可轻松扩展
提供多线程和分布式支持
该框架的具体用法以及其帮助文档,请参考官网介绍,本文不做赘述。
第二步、实战
本文以本人慕课网(https://www.imooc.com/ ) 的文章(https://www.imooc.com/u/1175248/articles )为例进行数据抓取(抓的话就抓自己的就好了,抓别人的不是不可以,但最起码要标注上原作者)。
一般对爬虫来说,都需要对Html文本进行解析,然后根据特定的抽取规则获取相应的内容。因此实战的第一步就是分析html结构,整理文章相关(标题、作作者、发布时间和文章内容等等)的抽取规则。
以https://www.imooc.com/article/41600 该文章为例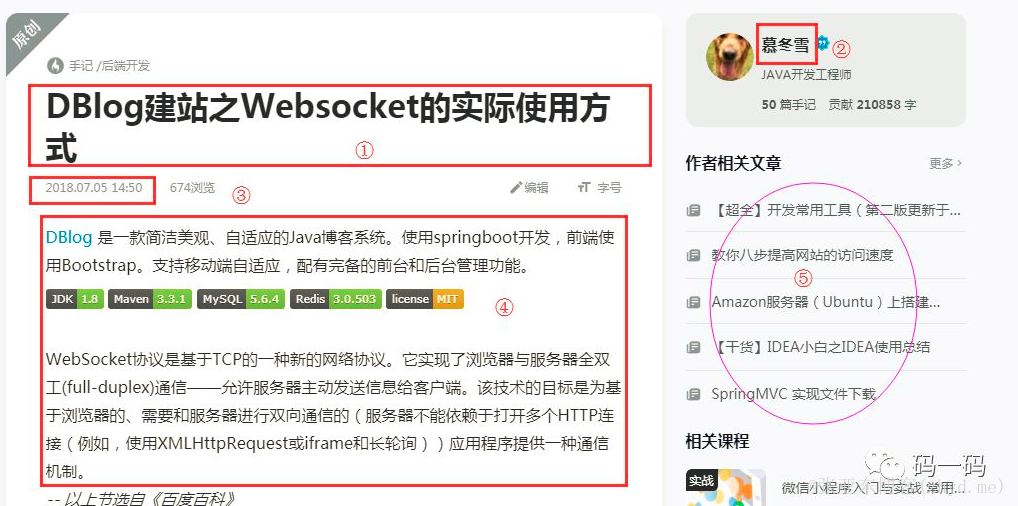
如图所示,需要抽取的一共为5部分:
文章标题
文章作者
文章发布日期
文章正文内容
待抽取的其他文章列表
f12查看页面结构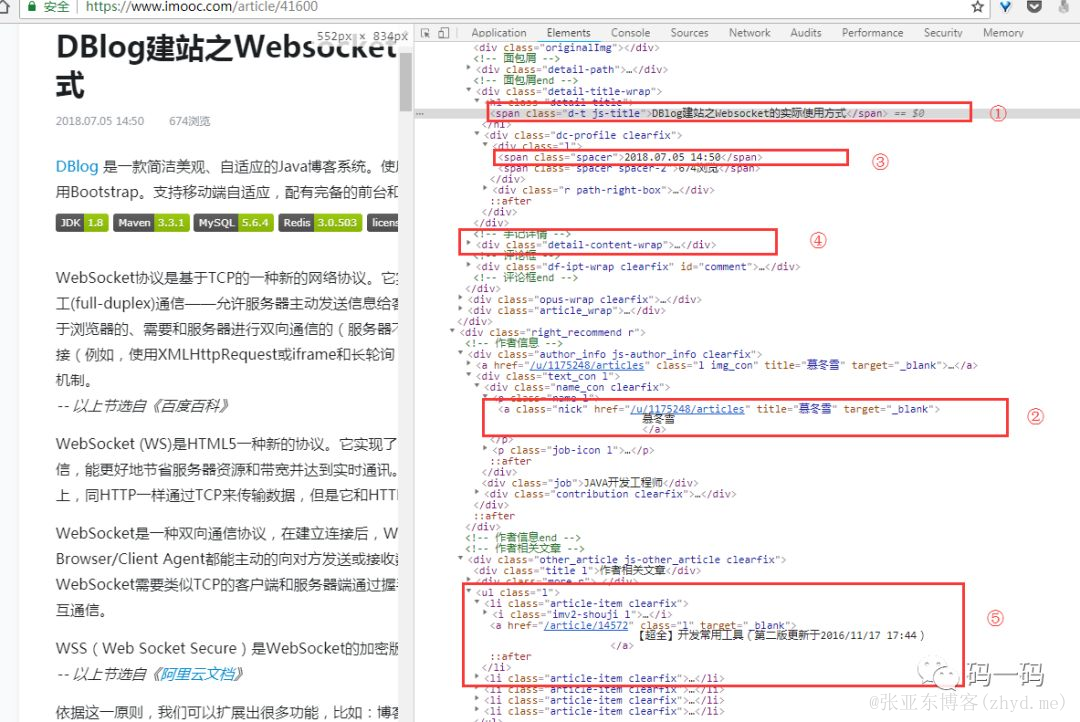
慕课的前端小伙伴还是很给力的,代码很整齐,因此抽取起来相对就简单的多!喏,整理相关规则如下:
标题://span[@class=js-title]/html()
作者://div[@class=name_con]/p[@class=name]/a[@class=nick]/html()
发布日期://div[@class='dc-profile']/div[@class='l']/span[@class='spacer']/text()
文章正文://div[@class=detail-content]/html()
待抽取的其他文章链接:/article/[0-9]{1,10}
接下来就要考虑账号登录的问题了,这一点,webMagic已经替我们留了接口了,在我们声明Site时,可以手动指定相关的Request参数,比如UA、Header以及Cookies,这几样我们都需要手动指定。具体的参数可以在浏览器中查看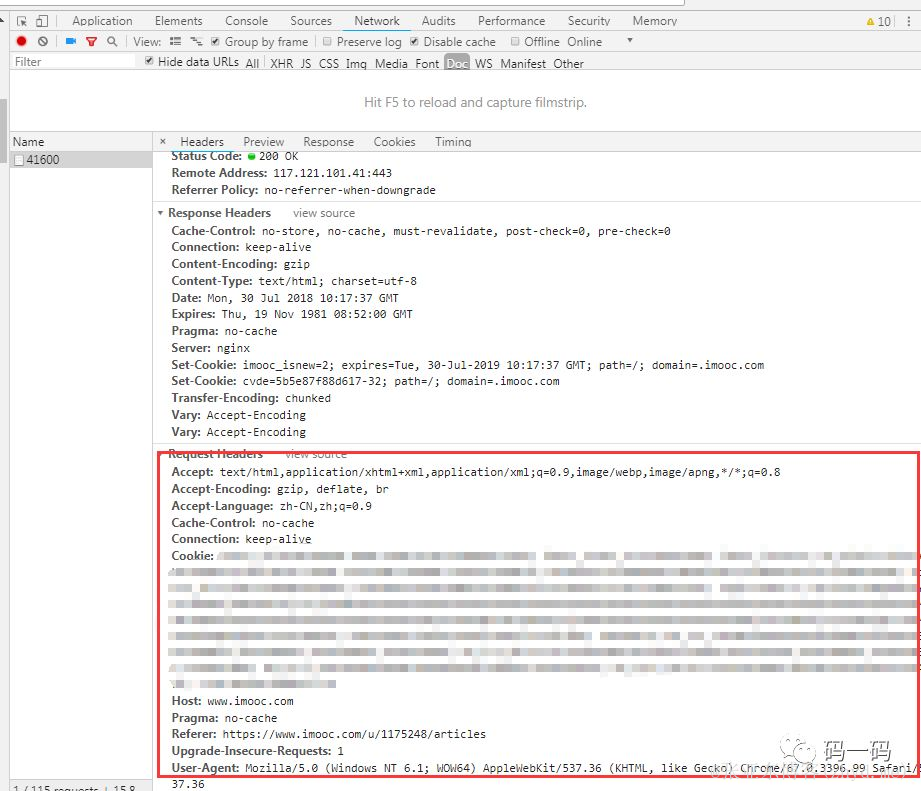
因为webMacgic不支持批量添加Cookie,所以我们需要将自己登陆后的Cookie逐条复制到程序中,可能有朋友会说,在Request Headers里的Cookie一大堆,一条条复制起来太难了!
就知道会有人这么问,办法已经给你们想好了,喏~~!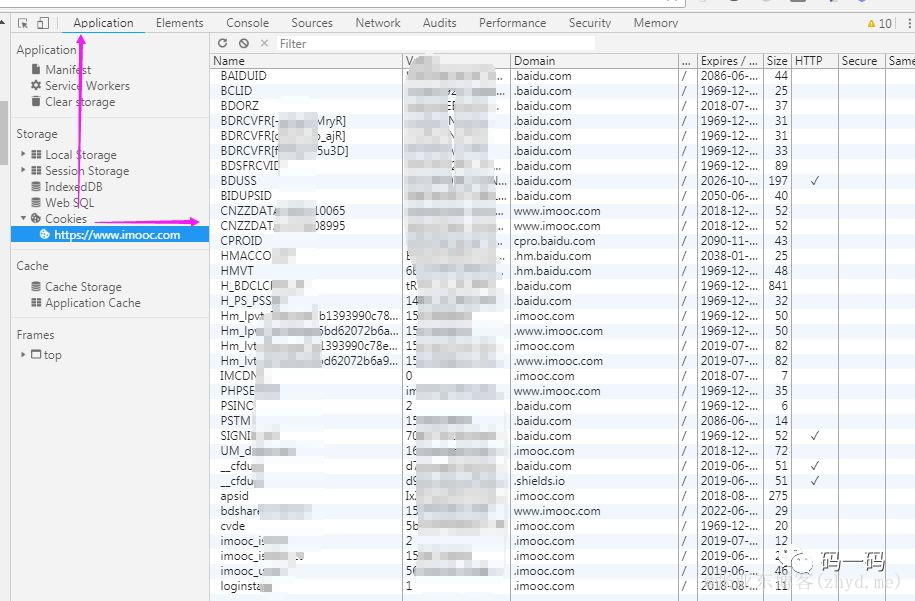
这个里面,一条条的,够方便了吧~~
接下来我可要上代码了~~!
首先添加依赖
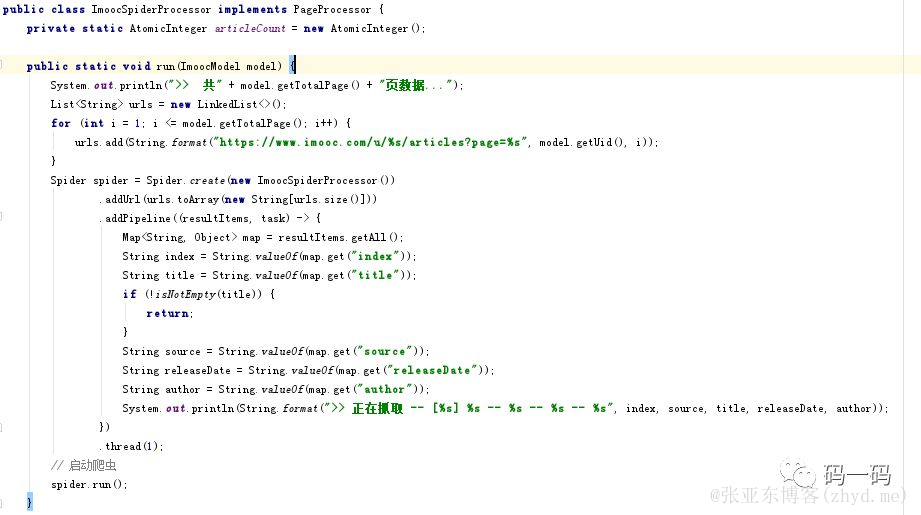
然后编写自己的Processor并实现PageProcessor接口,然后重写里面的process和getSite方法即可。
getSite(设置网站信息)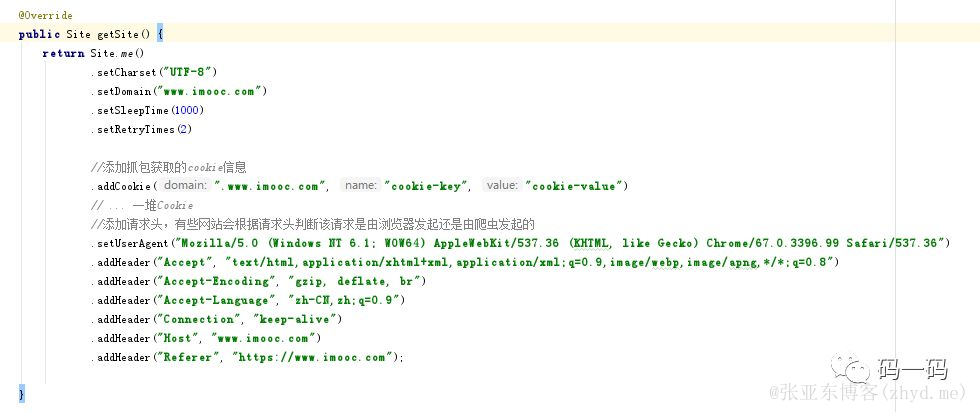
process(抽取页面内容)
run(自定义方法,爬虫的启动函数)
ImoocModel(参数类,很简单,就两个属性)

用户Id,和用户文章总页数,其中用户Id通过下面方式获取
运行测试
如图,文章已成功被抓取,剩下的,无非就是要么保存到文件中,要么持久化到数据库里。
第三步、总结
其实,本篇内容涉及到的技术并不难,主要重难点无非就一个:如何编写提取html内容的规则。规则一旦确定了,剩下的无非就是粘贴复制就能完成的代码而已。
还等什么,赶紧去试试啊~~~~
最后打个广告,如果你觉得这篇文章对你有用,可以关注我的技术公众号:码一码,你的关注和转发是对我最大的支持,O(∩_∩)O

- 本文标签: Java 爬虫 OneBlog
- 本文链接: https://zhyd.me/article/115
- 版权声明: 本文由张亚东原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐









相关文章
关于我

近期评论
-
来自: JustAuth于2019年7月21日正式喜提码云【GVP 】称号

-
来自: 留言板
-
来自: 暴露真实IP真的没关系吗?

-
来自: 留言板
-
来自: 留言板